
안녕하세요, 업브렐라 팀의 백엔드 남권우입니다.
이번 포스팅에서는 업브렐라의 아키텍처를 소개하고자 합니다.
가장 큰 고민은 어떻게하면 낮은 비용으로 고가용성의 아키텍처를 구축할 수 있을까였습니다. 또한 지속적인 서비스 운영을 고려했을 때 비용을 절감하는 것 또한 중요한 사안이었습니다.
1. 문제 정의
팀원들과 논의하며 어떤 아키텍처가 이상적일지 고민했었는데요, 아래와 같은 요구사항을 정리했습니다.
애플리케이션이 스래싱, 데드락 등으로 응답하지 않는 상태가 되어도 인스턴스 전체에 장애를 전파하지 않아야한다.
이전의 소규모 인프라에서 서비스를 구축했을 때, 공통적으로 나타났던 문제점은 애플리케이션 한 포인트에서 장애가 발생하면 서비스 전체로 장애가 전파된다는 점이었습니다. 단일 인스턴스로 이루어진 서비스에서는 이 문제를 해결하기가 쉽지 않았습니다. 따라서 서비스의 흐름에 따라 단일 장애 지점(SPOF)가 발생하는 경우를 방지하는 아키텍처를 구성하려 했습니다.
애플리케이션이 트래픽에 따라 유연한 확장(Scale-out)을 할 수 있다.
처음부터 서비스의 트래픽을 예측하기란 쉽지 않습니다. 높은 성능을 가진 서버를 구성하면 좋지만 비용적인 측면에서 많은 제약이 따릅니다. 따라서 서비스의 트래픽이 증가하면, 인스턴스의 수를 늘리는 스케일링이 필요합니다. 인스턴스를 늘리거나 줄이는 스케일링을 빠르게 자동화할 수 있어야 트래픽에 빠른 대응을 할 수 있습니다. 인스턴스의 수를 늘리는 작업을 자동화할 수 있는 AWS의 AutoScaling Group을 도입하였습니다.
특정 컨테이너가 다운되어도, 높은 가용성을 보장한다.
컨테이너는 인스턴스의 프로세스로 실행되기 때문에, 컨테이너가 다운되면 인스턴스 전체가 다운되는 문제가 발생합니다. 컨테이너가 다운되어도 장애가 발생하지 않으려면, 기본적으로 컨테이너가 이중화되어있어야 합니다. 각 컨테이너를 로드밸런서로 헬스체크하고, 컨테이너가 다운되면 로드밸런서에서 해당 컨테이너로 트래픽을 보내지 않도록 설정하면 컨테이너가 다운되어도 즉각적인 복구가 가능합니다.
스스로 컨테이너 복구와 인스턴스 복구를 진행한다.
컨테이너가 다운되면, 컨테이너를 복구해야 합니다. 이는 로드밸런서를 통해 헬스 체크가 지속적으로 이루어지고, 헬스 체크 응답이 반환되지 않는다면 ECS Agent를 통해 컨테이너를 재생성합니다. AWS 오토 스케일링 그룹에서는 인스턴스 단위의 복구도 제공합니다. 인스턴스가 반응하지 않을 때 인스턴스를 새로 생성하여 서비스를 복구합니다.
가용 영역(AZ) 단위의 장애가 발생해도 서비스가 중단되지 않는다.
가용 영역 단위의 장애가 발생하면, 해당 가용 영역의 인스턴스와 컨테이너가 모두 다운되어 서비스가 중단됩니다. 따라서 AWS의 AZ 단위 장애에 영향을 받지 않도록 여러 AZ에 걸친 인프라 구축이 필요했습니다.
이중화에 따른 세션 관리가 필요하다.
서비스를 이중화하게되면, 사용자의 세션은 EC2 인스턴스에 무관하게 동일하게 유지되어야 합니다. 따라서 한 곳에서 모든 세션 정보를 관리하기 위한 Redis 세션 서버도 도입하게 되었습니다.
2. ECS, ECR 도입
2.1. Elastic Container Service (ECS)
컨테이너와 인스턴스를 고가용성으로 유지하기 위해 컨테이너를 배포, 관리, 스케일링을 도와주는 컨테이너 오케스트레이션이 필요했습니다. 그 중에서 AWS에서 제공하는 ECS는 쉬운 설정으로 애플리케이션 구축에 집중할 수 있게 도와주는 서비스라고 합니다.
간단하게 ECS에 대해서 살펴보면, ECS는 아래와 같은 용량, 컨트롤러, 프로비저닝 3계층으로 구성됩니다.
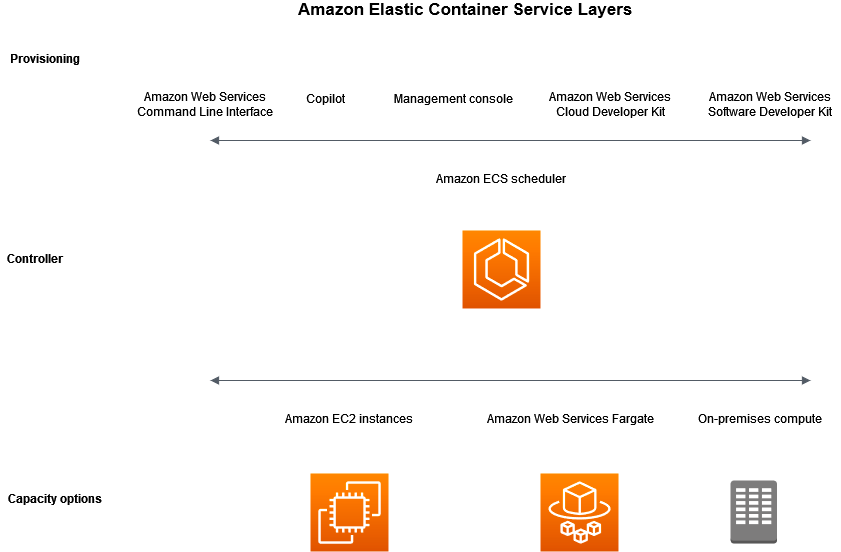
용량은 어떤 인프라에서 컨테이너를 실행할지 결정하는 계층입니다. EC2, Fargate 등이 있지만 업브렐라는 서버가 있는 환경인 EC2 컨테이너를 선택했습니다.
컨트롤러는 ECS에서 관리하는 인프라 인스턴스 내부에서 동작하는 애플리케이션을 관리하는 소프트웨어입니다.
다음으로 ECS의 관리 단위에 대해서 살펴보겠습니다. ECS는 내부적으로 클러스터, 서비스, 태스크로 세분화되어 관리됩니다. 그림으로 그리면 다음 그림과 같습니다.
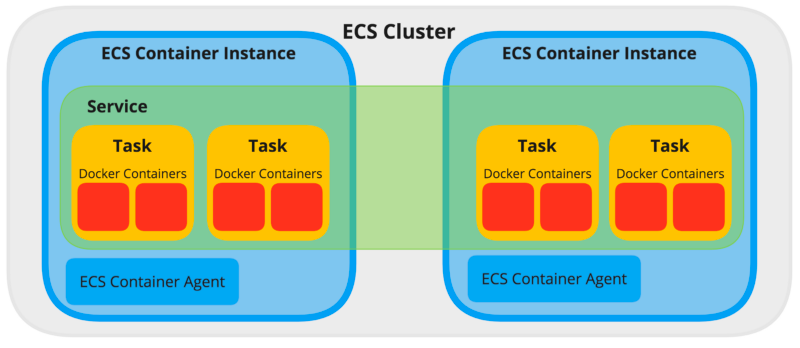
ECS 클러스터는 컨테이너를 실행하는 논리적인 공간입니다. 우리가 관리하고자하는 컨테이너 인스턴스들을 목적에 따라 논리적으로 묶어주는 그룹이 클러스터입니다.
ECS에서는 이 클러스터 내부에 오토스케일링 그룹에 따라 생성되는 인스턴스들을 등록합니다. 인스턴스 내부에는 각각 ECS 에이전트가 구동되어 인스턴스 내부의 컨테이너들에 대해 컨테이너를 증가시키거나 띄우는 등 오케스트레이션을 실행할 수 있게 되는 것입니다.
태스크는 컨테이너를 실행하는 최소 단위입니다. 그렇지만 컨테이너 1개가 태스크를 의미하지는 않고, 태스크 내부에 여러 컨테이너를 묶을 수 있습니다. 그리고 같은 태스크 내의 컨테이너는 같은 ECS 클러스터 인스턴스 내에 실행되도록 보장됩니다. 태스크를 정의하기 위해 AWS의 태스크 정의(Task Definition)을 설정해주어야 합니다. 태스크 정의에서는 역할, Docker 명령, CPU/Memory 할당 및 제한 등의 옵션을 설정할 수 있습니다.
서비스는 태스크들의 집합입니다. 서비스에서는 태스크의 실행 개수, 배포 방식, 실행 유형, 태스크 배치 전략 등을 설정하여 태스크를 관리합니다.
Elastic Container Registry (ECR)
ECR은 ECS와 연계되어 사용되는 서비스로, ECS에서 애플리케이션을 복구, 배포하기 위해 필요한 도커 이미지들을 저장하는 저장소입니다. 업브렐라에서는 Github Actions과 연계하여 빌드된 도커 이미지를 ECR에 업로드하는데, 이 과정도 다음 포스팅에서 자세히 다루겠습니다.
3. 업브렐라의 아키텍처 구성
3.1. 아키텍처 구성도
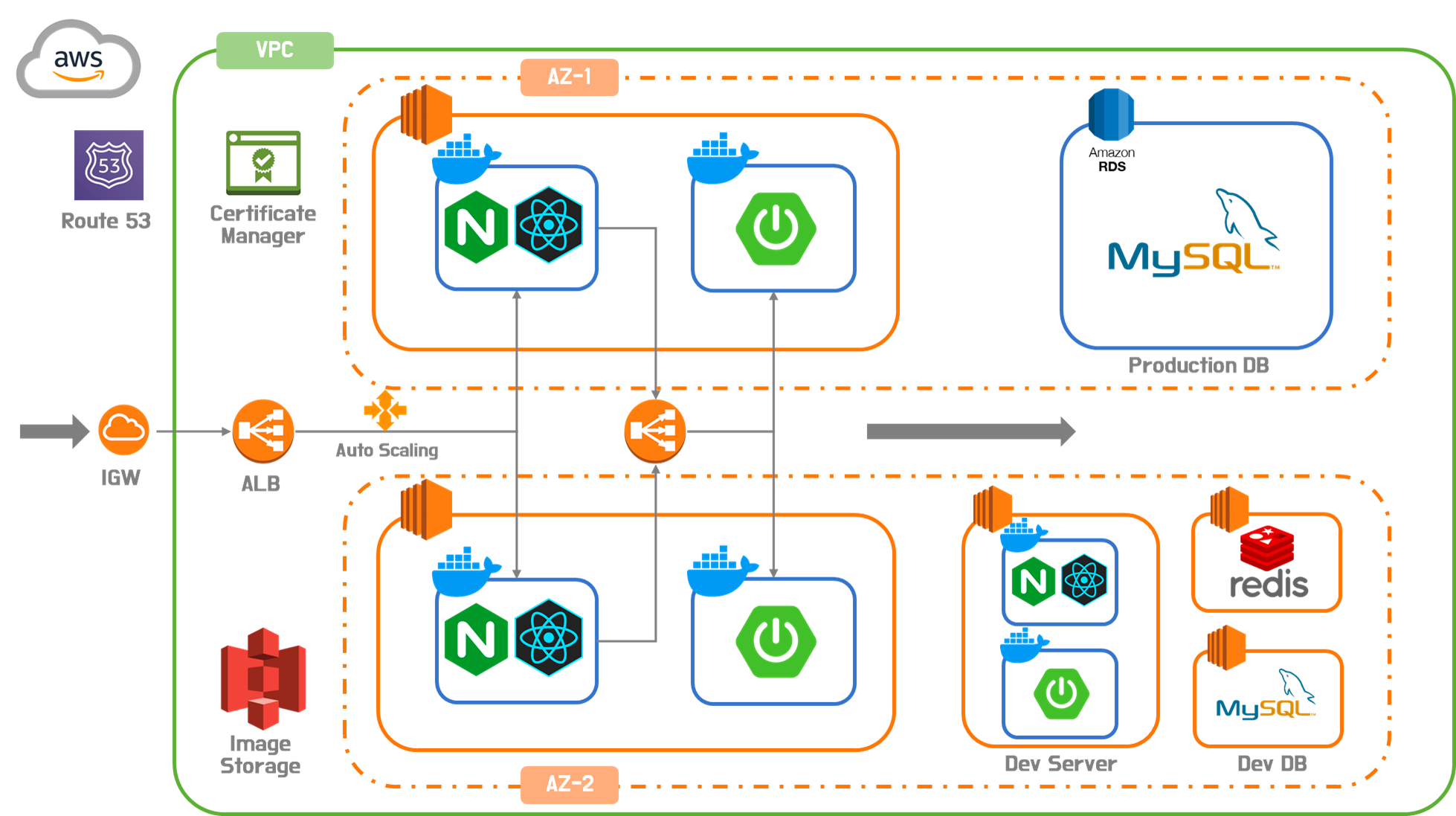
업브렐라의 아키텍처는 논리적으로 웹서버, WAS, DB로 구분되어 있으며, 물리적으로는 서버와 데이터베이스로 나뉘어집니다. 다만, 물리적인 EC2 인스턴스 한 대 내부에 웹서버, WAS 컨테이너를 구성하였습니다. 이 때 만약 특정 EC2 인스턴스의 웹 서버 컨테이너가 다운되었을 때 로드밸런서 없이 로컬 호스트 통신을 하게 되면 동일 인스턴스 내부의 WAS 컨테이너도 사용할 수 없는 상태가 됩니다. 따라서 별도의 로드밸런서를 두어 웹서버 컨테이너에서 보내는 트래픽을 받아 WAS에 다시 전송하는 구조를 설계했습니다. 이렇게 했을 때, 모든 컨테이너가 로드밸런서의 헬스체크를 독립적으로 받게 되며, 컨테이너가 다운되면 해당 컨테이너만 복구가 진행됩니다.
3.2. AZ 구성
업브렐라의 아키텍처는 AZ 단위 장애에 대응하기 위해 2개의 AZ에 걸쳐 구성되었습니다. 다만 데이터베이스는 비용적인 측면을 고려해서 Multi-AZ 구성을 하지 못하고 단일 AZ DB를 사용하였습니다. 따라서 현재는 사실 상 AZ 단위의 장애가 발생하면 문제가 발생하는 셈인데요. 추후에 서비스가 확장된다면 Multi-AZ로 마이그레이션하거나, EC2 인스턴스 2대로 직접 레플리카를 구성하는 방안을 고려하고 있습니다.
3.3. Auto Scaling Group 구성
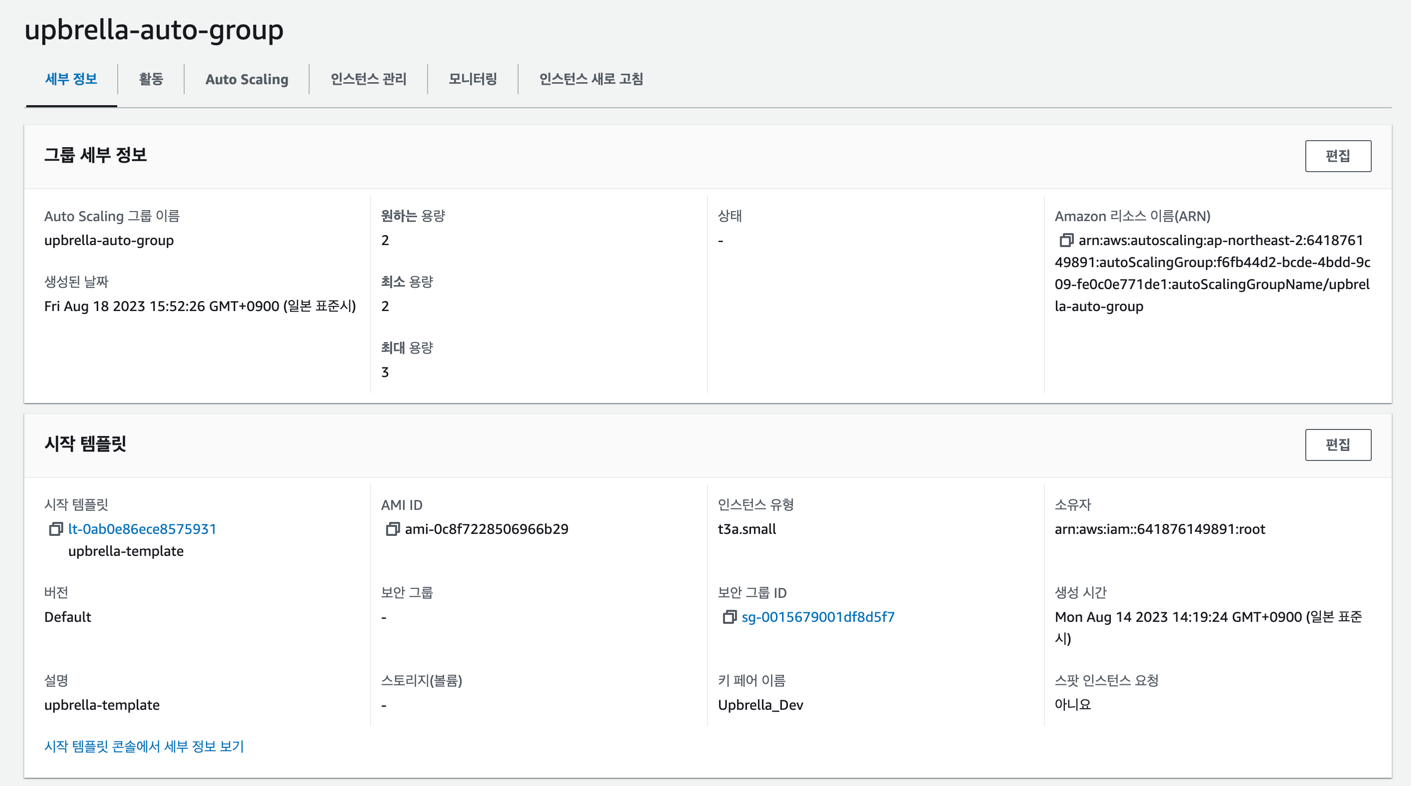
업브렐라의 Auto Scaling Group은 EC2 t3.small 인스턴스 최소 2대, 최대 3대로 구성되어 있습니다. 트래픽이 많이 발생한다면 3대까지 인스턴스가 늘어나 트래픽을 분산하고, 트래픽이 줄어들면 2대까지 인스턴스가 줄어들어 비용을 절감합니다.
오토 스케일링 그룹을 구성하기 위해, 시작 템플릿을 만들어야 합니다. 시작 템플릿은 오토 스케일링 그룹에서 스케일링을 통해 인스턴스를 생성할 때 사용하는 인스턴스의 템플릿입니다. 주의할 점은, 애플리케이션에 기본으로 사용하는 Image인 AMI를 선택할 때 ECS Optimized AMI를 선택해야 합니다. ECS 최적화된 AMI는 ECS 에이전트가 미리 설치되어 있어서 ECS 클러스터에 인스턴스를 등록할 때 편리합니다.
위에서 생성한 시작 템플릿을 사용하여 오토 스케일링 그룹을 생성합니다.
3.4. 로드밸런서 구성
업브렐라의 로드밸런서는 Application Load Balancer를 사용하였습니다. Application Load Balancer는 HTTP, HTTPS 트래픽을 처리할 수 있으며, 컨테이너 단위의 헬스체크를 지원합니다.
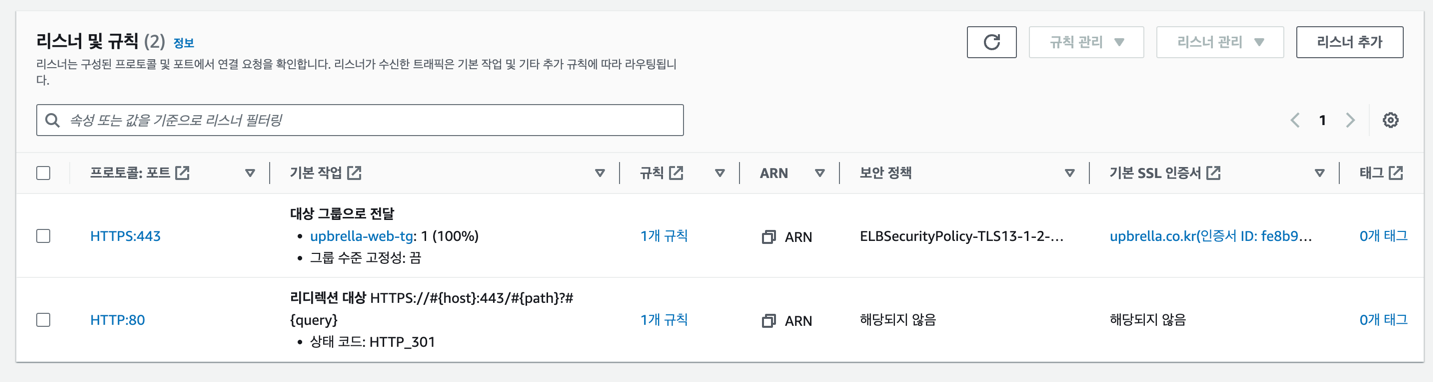
SSL 인증서는 AWS Certificate Manager를 사용하였습니다. Route 53로 ALB를 DNS로 연결시켜 주었고, TLS를 이용하기 때문에 HTTP로 접속했을 시 HTTPS로 리다이렉션하는 이벤트도 추가했습니다.
로드밸런서는 총 2대를 구성했는데, DNS가 연결된 로드밸런서에서 SSL 오프로딩이 일어나, ALB 이후 단에서는 HTTP 통신으로 내부적으로 통신이 이루어집니다.
3.5. ECS 클러스터, 서비스, 태스크 구성
위에서 ECS에 대해 살펴보았는데요, 이를 기반으로 어떻게 각 구성 단위를 설정했는지 살펴보겠습니다.
업브렐라에서는 WAS와 Web 서버 각각의 도커 이미지가 ECR에 등록되어 있습니다. 그리고 각 이미지는 서로 독립적으로 실행, 관리되어야 하므로 별도의 태스크로 생성하였습니다.
업브렐라 서비스 전체를 묶는 클러스터를 생성했고, 아래 그림처럼 클러스터 내부에는 2개의 인스턴스가 관리됩니다. 그리고 웹 서비스와 WAS 서비스가 클러스터 내부에서 동작하기 때문에 각 서비스를 생성해주었습니다.
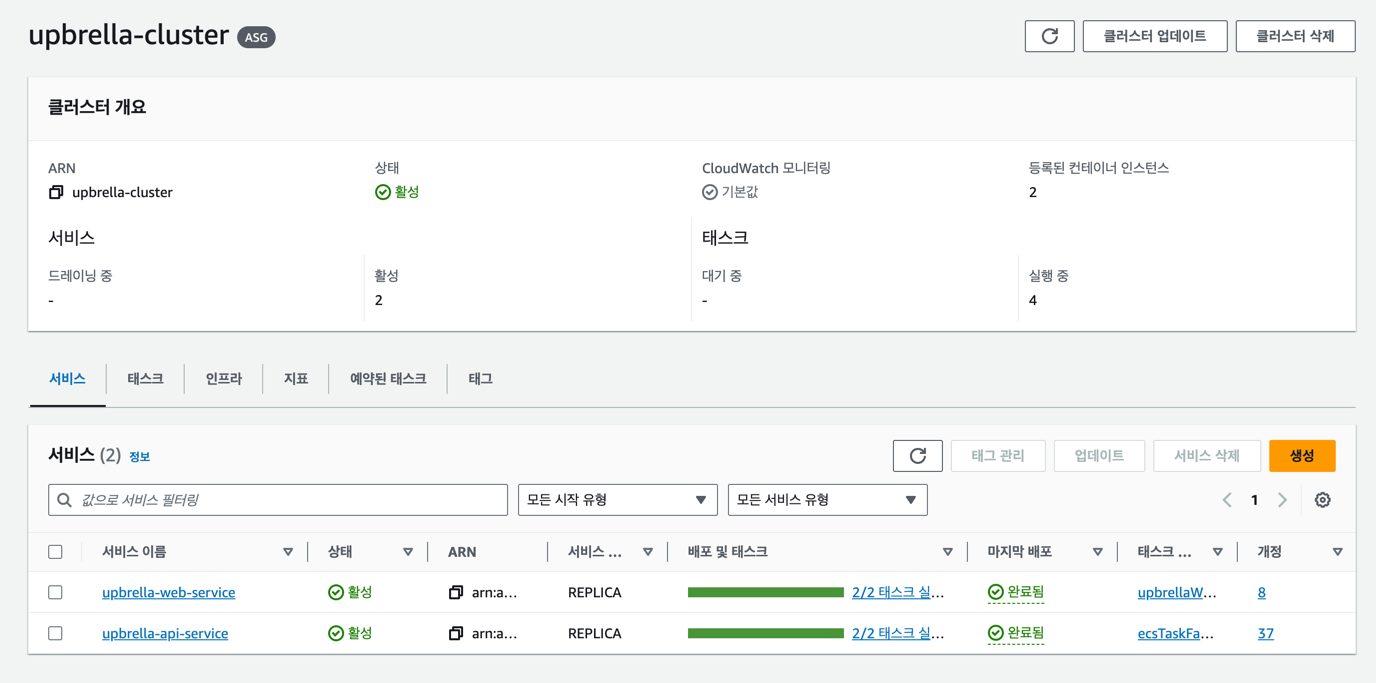
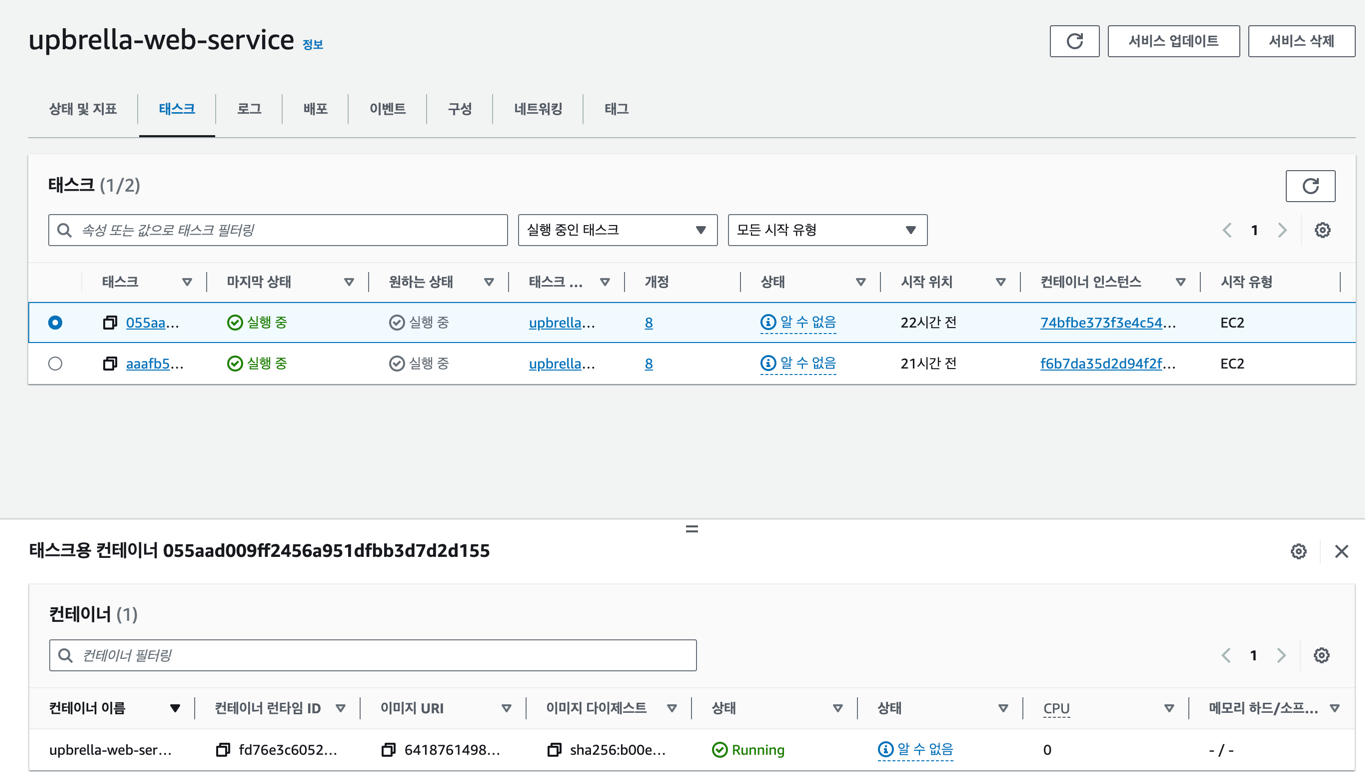
서비스는 태스크의 묶음이기 때문에 2개의 인스턴스에 2개의 태스크가 생성되는 서비스를 생성하였습니다. 이 때, 서비스에서 정의된 태스크 배치 전략에 따라 2개의 인스턴스에 각각 1개의 태스크가 배치되어 실행됩니다.
4. 사용해보니..
설정이 어려웠지만 사용해보니 아래 장점들이 체감되었습니다.
복구가 빠르다.
컨테이너가 꺼져도 로드밸런서를 통해 상태를 감지하기 때문에 빠른 복구되는 가용성이 체감되었습니다.
스케일링이 쉽다
트래픽에 따라 태스크 개수를 늘리기만하면 아주 쉽게 스케일링을 할 수 있었습니다.
설정이 쉽다.
위 장점들은 사실 컨테이너 오케스트레이션의 장점인데요, 설정이 굉장히 어렵다고 알려져있는 EKS, 쿠버네티스에 비해 간단하게 설정하여 사용할 수 있어서 좋았습니다. (물론 처음 사용하는 입장에서는 어려웠습니다..)
다음 포스팅에는 이어서 인프라에서 CI/CD 파이프라인을 구축하는 과정을 다뤄보겠습니다.